Large Multimodal Models (LMMs) have made significant strides in visual question-answering for single images. Recent advancements like long-context LMMs have allowed them to ingest larger, or even multiple, images. However, the ability to process a large number of visual tokens does not guarantee effective retrieval and reasoning for multi-image question answering (MIQA), especially in real-world applications like photo album searches or satellite imagery analysis. In this work, we first assess the limitations of current benchmarks for long-context LMMs. We address these limitations by introducing a new vision-centric, long-context benchmark, "Visual Haystacks (VHs)". We comprehensively evaluate both open-source and proprietary models on VHs, and demonstrate that these models struggle when reasoning across potentially unrelated images, perform poorly on cross-image reasoning, as well as exhibit biases based on the placement of key information within the context window. Towards a solution, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), an open-source, lightweight visual-RAG framework that processes up to 10k images on a single 40G A100 GPU -- far surpassing the 1k-image limit of contemporary models. MIRAGE demonstrates up to 13% performance improvement over existing open-source LMMs on VHs, sets a new state-of-the-art on the RetVQA multi-image QA benchmark, and achieves competitive performance on single-image QA with state-of-the-art LMMs.
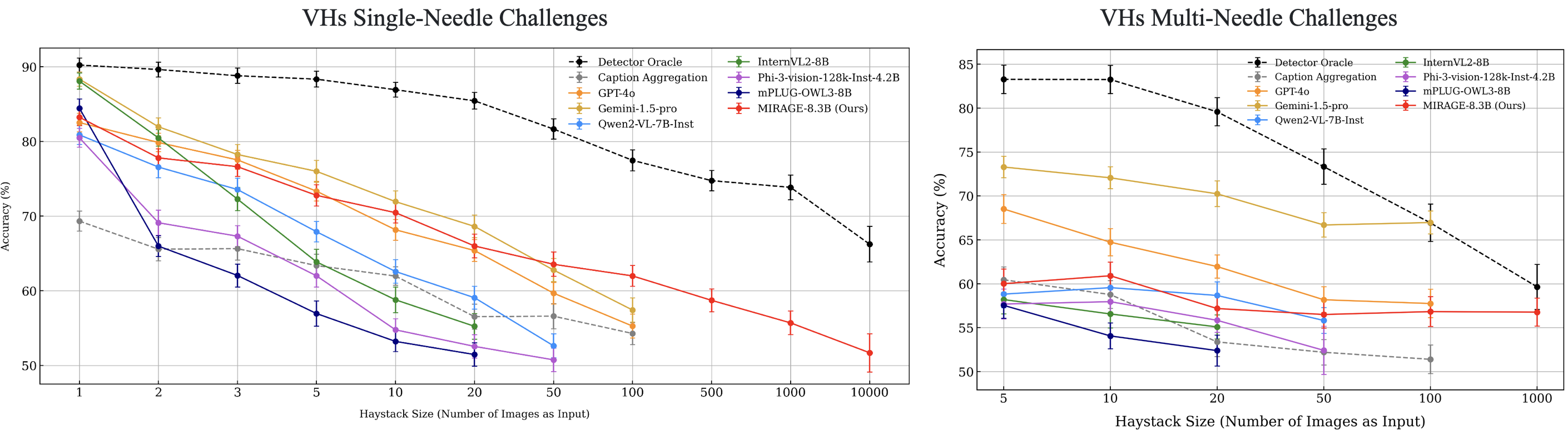
Visual Haystacks (VHs) is a "vision-centric" Needle-In-A-Haystack (NIAH) benchmark specifically designed to evaluate the capabilities of Large Multimodal Models (LMMs) in visual retrieval and reasoning over sets of unrelated images. Unlike conventional NIAH challenges that center on artificial, text-related retrieval and understanding with limited anecdotal examples, VHs contains a much larger number of examples and focuses on "simple visual tasks", providing a more accurate reflection of LMMs' capabilities when dealing with extensive visual context.
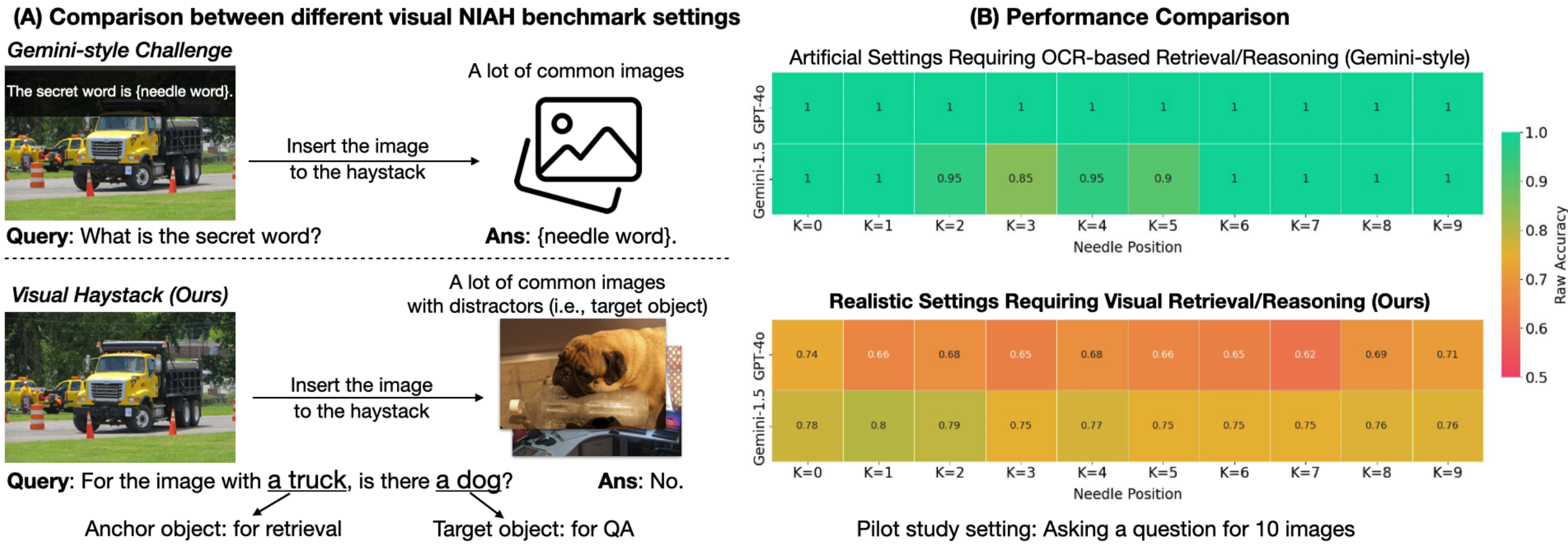
The dataset is derived from the in-domain COCO dataset and includes straightforward questions, focusing exclusively on long-context visual retrieval and reasoning capabilities. It features two types of challenges: the Single-Needle Challenge and the Multi-Needle Challenge. For more information, please visit our GitHub repository.
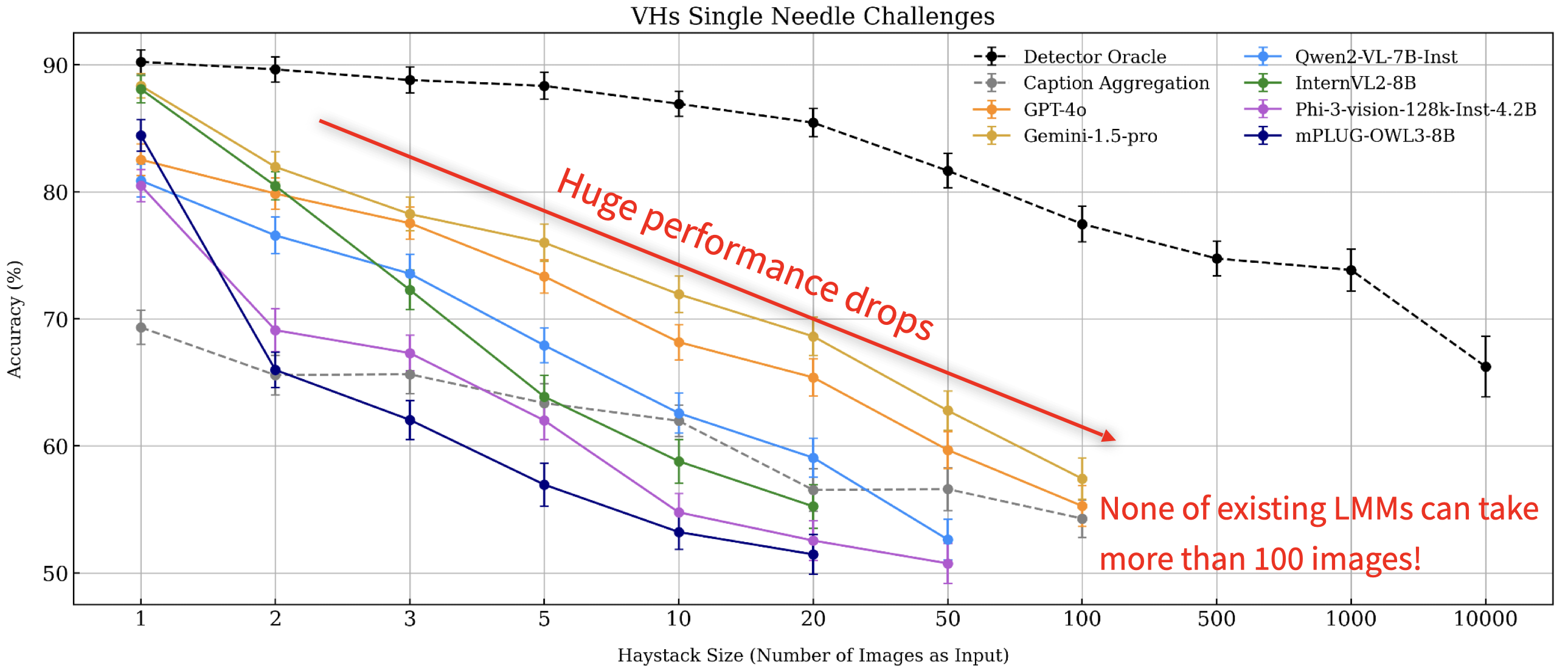
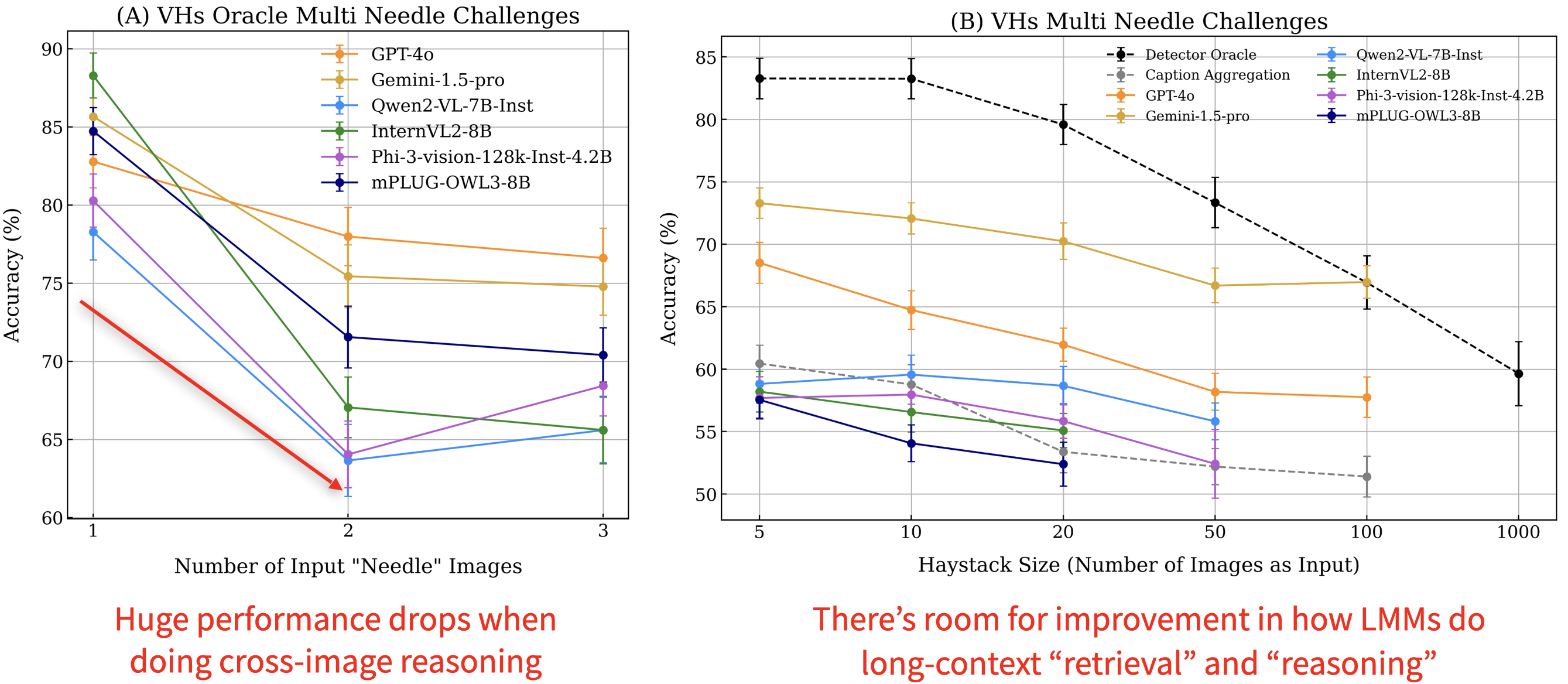
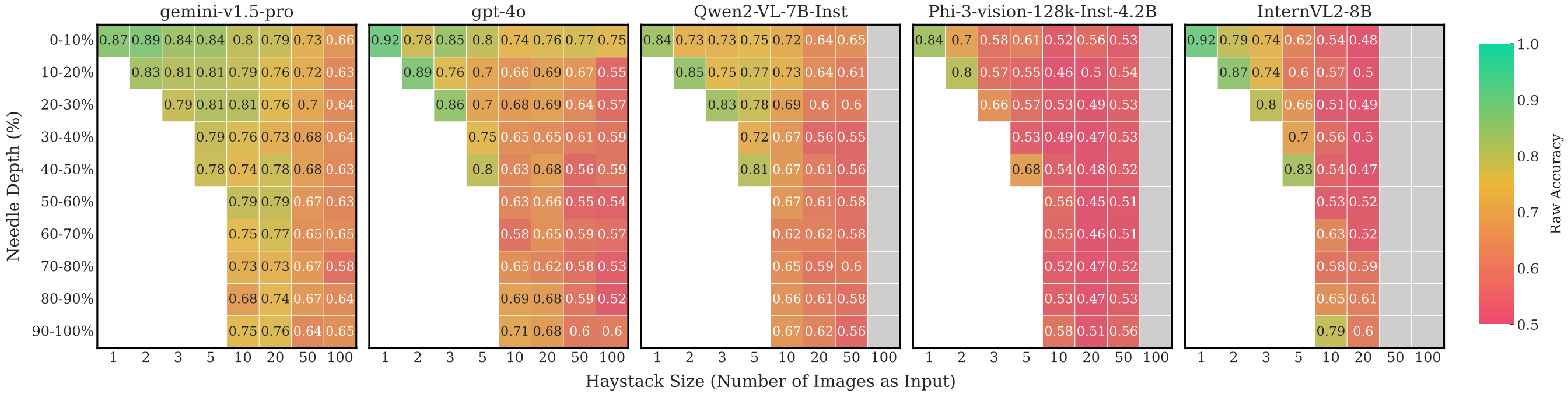
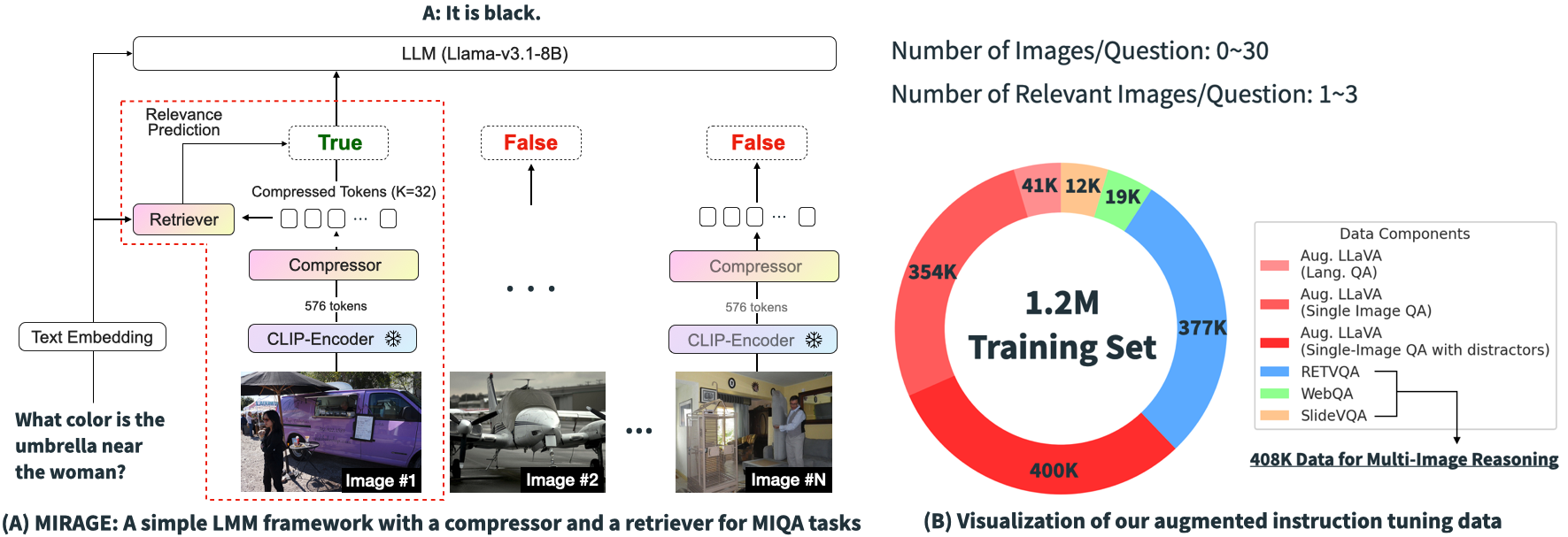
Through extensive experiments above, we demonstrated that existing LMMs struggle with inputs exceeding 100 images due to API limitations, context overflow, or hardware constraints on 4 A100 GPUs. Also, these models often face issues such as visual distractions, cross-image reasoning difficulties, and positional biases. To overcome these challenges, we developed MIRAGE (8.3B), a pioneering, open-source visual-RAG baseline model based on LMMs capable of handling tens of thousands of images.

@inproceedings{
wu2025visual,
title={Visual Haystacks: A Vision-Centric Needle-In-A-Haystack Benchmark},
author={Tsung-Han Wu and Giscard Biamby and Jerome Quenum and Ritwik Gupta and Joseph E. Gonzalez and Trevor Darrell and David Chan},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=9JCNPFL1f9}
}